사용자 정의 모델과 훈련 알고리즘
가장 간단하고 많이 사용하는 사용자 정의 손실 함수를 만들어보겠습니다.
사용자 정의 손실 함수
회귀 모델을 훈련하는 데 훈련 세트에 잡음 데이터가 조금 있을 때,
이상치를 제거하거나 고쳐서 데이터셋을 수정할 수 있지만, 비효율적이고 잡음이 여전히 있을 수 있습니다.
이럴 때 평균 제곱 오차를 쓰면 큰 오차에 너무 과한 벌칙을 가해서 정확하지 않은 모델이 만들어질 것이고,
평균 절댓값 오차는 이상치에 관대해서 훈련이 수렴되기까지 식나이 걸리고 모델이 정밀하지 않을 것입니다.
이런 경우 후버 손실을 사용하면 좋습니다.
후버 손실은 아직 케라스 공식 API에서 지원하지 않습니다.
tf.keras에서는 지원하기는 하지만, (keras.losses.Huber 클래스를 사용하면 됩니다.) 없다고 생각하고 구현해보겠습니다.
그냥 레이블과 예측을 매개변수로 받는 함수를 만들고 텐서플로 연산을 이용해 샘플의 손실을 계산하면 됩니다.
def huber_fn(y_true, y_pred):
error = y_true - y_pred
is_small_error = tf.abs(error) < 1
squared_loss = tf.square(error) / 2
linear_loss = tf.abs(error) - 0.5
# small_error라면 squared_loss를, 아니라면 linear_loss를 적용
return tf.where(is_small_error, squared_loss, linear_loss)전체 손실의 평균이 아니라 샘플마다 하나의 손실을 담은 텐서를 반환하는 게 좋습니다.
이렇게 해야 필요할 때 케라스가 클래스 가중치나 샘플 가중치를 적용할 수 있습니다.
이제 이렇게 만든 손실을 사용해 모델을 컴파일하고 훈련할 수 있습니다.
model.compile(loss=huber_fn, optimizer='nadam')
model.fit(X_train, y_train, [...])사용자 정의 요소를 가진 모델을 정의하고 로드하기
케라스가 함수 이름을 저장하므로 사용자 정의 손실 함수를 저장하는 데는 이상이 없습니다.
모델을 로드할 때 함수 이름과 실제 함수를 매핑한 딕셔너리를 전달해야 합니다.
좀 더 일반적으로 말하면 사용자 정의 객체를 포함한 모델을 로드할 때는 그 이름과 객체를 매핑해야 합니다.
model = keras.models.load_model('my_model_with_a_custom_loss.h5',
custom_objects={'huber_fn': huber_fn})후버 함수를 아래와 같이 좀 더 일반적으로 쓸 수도 있습니다.
def create_huber(threshold=1.0):
def huber_fn(y_true, y_pred):
error = y_true - y_pred
is_small_error = tf.abs(error) < threshold
squared_loss = tf.square(error) / 2
linear_loss = threshold * tf.abs(error) - threshold ** 2 / 2
# small_error라면 squared_loss를, 아니라면 linear_loss를 적용
return tf.where(is_small_error, squared_loss, linear_loss)
return huber_fn
model.compile(loss=create_huber(2.0), optimizer='nadam')
그런데 이렇게 하면 모델에 threshold값은 저장되지 않습니다.
따라서 load 시에 threshold 값을 또 지정해줘야 합니다.
model = keras.models.load_model('my_model_with_a_custom_loss_threshold_2.h5',
custom_objects={'huber_fn': create_huber(2.0)})이 문제는 keras.losses.Loss 클래스를 상속하고 get_config() 메소드를 구현해서 해결할 수 있습니다.
class HuberLoss(keras.losses.Loss):
# 생성자는 기본적 하이퍼파라미터를 **kwargs로 받아서 부모 클래스의 생성자에게 전달합니다.
def __init__(self, threshold=1.0, **kwargs):
self.threshold = threshold
super().__init__(**kwargs)
# call() 메소드는 레이블과 예측을 받고 모든 샘플의 손실을 계산해 반환합니다.
def call(self, y_true, y_pred):
error = y_true - y_pred
is_small_error = tf.abs(error) < self.threshold
squared_loss = tf.square(error) / 2
linear_loss = self.threshold * tf.abs(error) - self.threshold**2 / 2
return tf.where(is_small_error, squared_loss, linear_loss)
# 하이퍼파라미터 이름과 같이 매핑된 딕셔너리를 반환합니다.
# 부모 클래스의 get_config() 메소드를 호출하고 반환된 딕셔너리에 새 하이퍼파라미터를 추가합니다.
def get_config(self):
base_config = super().get_config()
return {**base_config, "threshold": self.threshold}이렇게 하면 모델을 컴파일할 때 이 클래스의 인스턴스를 사용할 수 있습니다.
model.compile(loss=HuberLoss(2.), optimizer='nadam')이 모델을 저장할 때 threshold도 함께 저장됩니다.
모델을 로드할 때 클래스 이름과 클래스 자체를 매핑해줘야 합니다.
model = keras.models.load_model('my_model_with_a_custom_loss_class.h5',
custom_objects={'HuberLoss': HuberLoss})활성화 함수, 초기화, 규제, 제한을 커스터마이징하기
손실, 규제, 제한, 초기화, 지표, 활성화 함수, 층, 모델과 같은 대부분의 케라스 기능은 유사한 방법으로 커스터마이징 할 수 있습니다. 다음은 그 예시입니다.
def my_softplus(z): # tf.nn.softplus(z) 와 동일
return tf.math.log(tf.exp(z) + 1.0)
def my_glorot_initializer(shape, dtype=tf.float32): # keras.initializers.glorot_normal() 과 동일
stddev = tf.sqrt(2. / (shape[0] + shape[1]))
return tf.random.normal(shape, stddev=stddev, dtype=dtype)
def my_l1_regularizer(weights): # keras.regularizers.l1(0.01) 과 동일
return tf.reduce_sum(tf.abs(0.01 * weights))
def my_positive_weights(weights): # tf.nn.relu(weights) 와 동일
return tf.where(weights < 0., tf.zeros_like(weights), weights)매개변수는 함수의 종류에 따라 다릅니다.
이렇게 만든 함수는 아래와 같이 보통의 함수와 동일하게 사용가능합니다.
layer = keras.layers.Dense(1, activation=my_softplus,
kernel_initializer=my_glorot_initializer,
kernel_regularizer=my_l1_regularizer,
kernel_constraint=my_positive_weights)함수가 모델과 함께 저장해야 할 하이퍼파라미터가 있다면 keras.regularizers.Regularizer, keras.constraints.Constraint, keras.initializers.Initializer, keras.layers.Layer와 같이 적절한 클래스를 상속합니다. 다음은 factor 하이퍼파라미터를 저장하는 \(l_{1}\) 규제를 위한 간단한 클래스의 예시입니다. (부모 클래스에 생성자와 get_config() 메소드가 정의되지 않아서 호출할 필요가 없습니다.)
class MyL1Regularizer(keras.regularizers.Regularizer):
def __init__(self, factor):
self.factor = factor
def __call__(self, weights):
return tf.reduce_sum(tf.abs(self.factor * weights))
def get_config(self):
return {"factor": self.factor}사용자 정의 지표
손실과 지표는 개념적으로 다른 것은 아닙니다.
손실은 모델을 훈련하기 위해 경사 하강법에서 사용하므로 미분 가능해야 하고 그레이디언트가 모든 곳에서 0이 아니어야 하고 사람이 쉽게 이해할 수 없어도 괜찮습니다.
하지만 지표는 모델을 평가할 때 사용합니다. 미분이 가능하지 않거나 그레이디언트가 0이 아닌 곳이 있어도 됩니다. 그리고 훨씬 이해하기 쉬워야 합니다.
그렇지만 대부분 사용자 지표 함수를 만드는 것은 사용자 손실 함수를 만드는 것과 동일합니다.
예를 들어 아래와 같이 컴파일된 모델이 있다고 하겠습니다.
model.compile(loss='mse', optimizer='nadam', metrics=[create_huber(2.0)])훈련하는 동안 각 배치에 대해 지표를 계산하고 계속 평균을 기록합니다.
이 방식이 대부분의 경우에 맞지만, 항상 그렇지는 않습니다.
예를 들어 이진 분류기의 정밀도를 생각해보면,
처음에 5개의 양성 예측 중 4개가 맞아서 80%의 정밀도를 기록하고,
두 번째에 3개의 양성 예측이 모두 틀려서 0%의 정밀도를 기록했다고 하겠습니다.
이 둘을 평균을 내면 정밀도는 40%이지만,
실제 정밀도를 계산해보면 4 / (5 + 3) 이라서 50%가 전체 정밀도가 됩니다.
따라서 진짜 양성과 거짓 양성을 기록하고 계산할 객체가 필요합니다.
keras.metrics.Precision 클래스가 이 일을 합니다.
이런 스트리밍 지표를 만들고 싶다면 keras.metrics.Metric 클래스를 상속하면 됩니다.
다음은 전체 후버 손실과 지금까지 처리한 샘플 수를 기록하는 클래스입니다.
class HuberMetric(keras.metrics.Metric):
def __init__(self, threshold=1.0, **kwargs):
super().__init__(**kwargs) # 기본 매개변수 처리 (예를 들면, dtype)
self.threshold = threshold
self.huber_fn = create_huber(threshold)
# add_weight 메소드로 지표 상태 기록을 위한 변수를 만듭니다.
self.total = self.add_weight("total", initializer="zeros")
self.count = self.add_weight("count", initializer="zeros")
# 이 클래스를 함수처럼 사용할 때 호출됩니다.
# 배치의 레이블과 예측을 기반으로 변수를 업데이트합니다.
def update_state(self, y_true, y_pred, sample_weight=None):
metric = self.huber_fn(y_true, y_pred)
self.total.assign_add(tf.reduce_sum(metric))
self.count.assign_add(tf.cast(tf.size(y_true), tf.float32))
# 최종 결과를 계산하고 반환합니다.
# 이 지표 클래스를 함수처럼 사용하면 먼저 update_state()가 호출되고 result()가 호출됩니다.
def result(self):
return self.total / self.count
# threshold 변수를 모델과 함께 저장합니다.
def get_config(self):
base_config = super().get_config()
return {**base_config, "threshold": self.threshold}
# reset_status()는 기본적으로 모든 변수를 0.0으로 초기화합니다. (필요하면 override)사용자 정의 층
이따금 텐서플로에 없는 특이한 층을 만들어야 할 수도 있습니다.
먼저 keras.layers.Flatten이나 keras.layers.ReLU처럼 가중치가 필요 없는 층을 만들려면 파이썬 함수를 만든 후 keras.layers.Lambda 층으로 감싸는 것입니다.
exponential_layer = keras.layers.Lambda(lambda x: tf.exp(x))이런 사용자 정의 층을 시퀀셜 API나 함수형 API, 서브클래싱 API에서 보통의 층과 동일하게 사용할 수 있습니다.
상태가 있는 층을 만들려면 keras.layers.Layer 클래스를 상속해야 합니다.
예를 들면 다음과 같이 Dense 층의 간소화 버전을 만들 수 있습니다.
class MyDense(keras.layers.Layer):
# 모든 하이퍼파라미터를 매개변수로 받습니다.
# 전달받은 **kwargs 매개변수를 부모 생성자에 전달합니다. (input_shape, trainable 등)
def __init__(self, units, activation=None, **kwargs):
super().__init__(**kwargs)
self.units = units
self.activation = keras.activations.get(activation) # 문자열에 해당하는 활성화 함수 가져오기
# 가중치마다 add_weight()를 호출하여 층의 변수를 만듭니다.
# 이 메소드는 층이 처음 만들어질 때 호출됩니다.
def build(self, batch_input_shape):
# 연결 가중치 추가
self.kernel = self.add_weight(
name="kernel", shape=[batch_input_shape[-1], self.units],
initializer="glorot_normal")
# bias 추가
self.bias = self.add_weight(
name="bias", shape=[self.units], initializer="zeros")
# 아래 줄로 층이 만들어졌다는 걸 인식하게 합니다. (self.built=True로 설정)
super().build(batch_input_shape) # must be at the end
# 이 층에 필요한 연산 수행, 입력과 커널을 행렬 곱셈하고 편향을 더합니다.
def call(self, X):
return self.activation(X @ self.kernel + self.bias)
# 이 층의 출력 크기를 반환합니다.
def compute_output_shape(self, batch_input_shape):
return tf.TensorShape(batch_input_shape.as_list()[:-1] + [self.units])
# 앞서 보았던 것과 같습니다.
# 다만 keras.activations.serialize()를 활용해 활성화 함수의 전체 설정을 저장합니다.
def get_config(self):
base_config = super().get_config()
return {**base_config, "units": self.units,
"activation": keras.activations.serialize(self.activation)}이렇게 하면 MyDense 층을 다른 층과 동일하게 쓸 수 있습니다.
여러 입력을 받는 층을 만들려면 call() 메소드에 모든 입력이 포함된 튜플을 매개변수 값으로 전달해야 합니다.
비슷하게 compute_output_shape() 메소드의 매개변수도 각 입력의 배치 크기를 담은 튜플이어야 합니다.
여러 출력을 가진 층을 만들려면 call() 메소드가 출력의 리스트를 반환해야 합니다.
compute_output_shape() 메소드는 배치 출력 크기의 리스트를 반환해야 합니다.
다음은 두 개의 입력을 받고 세 개의 출력을 하는 층의 예시입니다.
class MyMultiLayer(keras.layers.Layer):
def call(self, X):
X1, X2 = X
print("X1.shape: ", X1.shape ," X2.shape: ", X2.shape) # 사용자 정의 층 디버깅
return X1 + X2, X1 * X2
def compute_output_shape(self, batch_input_shape):
batch_input_shape1, batch_input_shape2 = batch_input_shape
return [batch_input_shape1, batch_input_shape2]이렇게 만든 층 역시 다른 일반적인 층처럼 사용할 수 있습니다.
하지만 함수형 API와 서브클래싱 API에만 사용할 수 있습니다.
시퀀셜 API에 하나의 입력과 하나의 출력만 사용하므로 사용할 수 있습니다.
훈련과 테스트에서 다르게 동작하는 층이 필요하다면 call() 메소드에 training 매개변수를 추가하여 훈련인지 테스트인지를 결정해야 합니다. 예를 들어 훈련 동안 규제 목적으로 가우스 잡음을 추가하고 테스트 시에는 아무것도 하지 않는 층을 만들어보겠습니다. (케라스에 이미 이런 일을 하는 keras.layers.GaussianNoise 층이 있습니다.)
class AddGaussianNoise(keras.layers.Layer):
def __init__(self, stddev, **kwargs):
super().__init__(**kwargs)
self.stddev = stddev
def call(self, X, training=None):
if training:
noise = tf.random.normal(tf.shape(X), stddev=self.stddev)
return X + noise
else:
return X
def compute_output_shape(self, batch_input_shape):
return batch_input_shape사용자 정의 모델
사용자 정의 모델 클래스를 만들려면 keras.Model 클래스를 상속하고 생성자에서 층과 변수를 만들고 모델이 해야 할 작업을 call() 메소드에 구현합니다.
아래와 같은 구조를 가진 모델을 한 번 만들어보겠습니다. (이와 같은 구조는 실제 사용되는 게 아닙니다. 그냥 문법 활용을 위해 임의로 이러한 구조의 모델을 만드는 것입니다.)
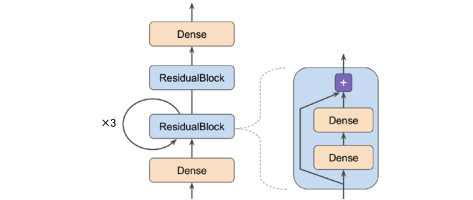
먼저 ResidualBlock 층의 코드입니다.
class ResidualBlock(keras.layers.Layer):
def __init__(self, n_layers, n_neurons, **kwargs):
super().__init__(**kwargs)
self.hidden = [keras.layers.Dense(n_neurons, activation="elu",
kernel_initializer="he_normal")
for _ in range(n_layers)]
def call(self, inputs):
Z = inputs
for layer in self.hidden:
Z = layer(Z)
return inputs + Z다음은 서브클래싱 API를 사용해 이 모델을 정의하겠습니다.
class ResidualRegressor(keras.models.Model):
def __init__(self, output_dim, **kwargs):
super().__init__(**kwargs)
self.hidden1 = keras.layers.Dense(30, activation="elu",
kernel_initializer="he_normal")
self.block1 = ResidualBlock(2, 30)
self.block2 = ResidualBlock(2, 30)
self.out = keras.layers.Dense(output_dim)
def call(self, inputs):
Z = self.hidden1(inputs)
for _ in range(1 + 3):
Z = self.block1(Z)
Z = self.block2(Z)
return self.out(Z)생성자에서 층을 만들고 call() 메소드에서 이를 사용합니다.
이 모델을 다른 일반 모델처럼 사용할 수 있습니다.
save()를 사용해 모델을 저장하고 keras.models.load_model() 을 사용해 저장된 모델을 로드하고 싶다면
ResidualBlock 클래스와 ResidualRegressor 클래스 모두에 get_config() 메소드를 구현해야 합니다.
또한 save_weights()와 load_weights() 메소드를 사용해 가중치를 저장, 로드할 수 있습니다.
모델 구성 요소에 기반한 손실과 지표
앞서 사용한 손실과 지표는 모두 레이블과 예측을 기반으로 한 것입니다.
그런데 은닉층의 가중치나 활성화 함수 등과 같이 모델의 구성 요소에 기반한 손실을 정의해야 할 때가 있습니다.
이런 손실은 규제나 모델의 내부 상황을 모니터링할 때 유용합니다.
모델 구성 요소에 기반한 손실을 정의하고 계산하여 add_loss() 메소드에 그 결과를 전달합니다.
예를 들어 다섯 개의 은닉층과 출력층으로 구성된 회귀용 MLP 모델을 만들어보겠습니다.
이 모델은 맨 위의 은닉층에 보조 출력을 가집니다.
이 보조 출력에 연결된 손실을 재구성 손실이라고 합니다.
즉 재구성과 입력 사이의 평균 제곱 오차입니다.
재구성 손실을 주 손실에 더해 회귀 작업에 직접적으로 도움이 되지 않은 정보일지라도 모델이 은닉층을 통과하며 가능한 많은 정보를 유지하게 유도합니다. 사실 이런 손실이 이따금 일반화 성능을 향상시킵니다. 다음은 사용자 정의 재구성 손실을 가지는 모델을 만드는 코드입니다.
class ReconstructingRegressor(keras.Model):
def __init__(self, output_dim, **kwargs):
super().__init__(**kwargs)
self.hidden = [keras.layers.Dense(30, activation="selu",
kernel_initializer="lecun_normal")
for _ in range(5)]
self.out = keras.layers.Dense(output_dim)
self.reconstruction_mean = keras.metrics.Mean(name="reconstruction_error")
def build(self, batch_input_shape):
n_inputs = batch_input_shape[-1]
self.reconstruct = keras.layers.Dense(n_inputs)
super().build(batch_input_shape)
def call(self, inputs):
Z = inputs
for layer in self.hidden:
Z = layer(Z)
reconstruction = self.reconstruct(Z)
recon_loss = tf.reduce_mean(tf.square(reconstruction - inputs))
self.add_loss(0.05 * recon_loss) # 재구성 손실이 주 손실을 압도하지 않게 * 0.05
return self.out(Z)이와 비슷하게 모델의 구성 요소에 기반해 임의의 계산을 수행하는 사용자 정의 지표를 추가할 수 있습니다.
다만 결괏값이 지표 객체의 출력이어야 합니다.
예를 들면 생성자에서 keras.metrics.Mean 객체를 만들고 recon_loss 를 전달하면서 call() 메소드를 호출할 수 있습니다.
마지막으로 모델의 add_metric() 메소드를 호출해 모델에 이 지표를 추가합니다.
이렇게 하면 모델을 훈련할 때 케라스가 에포크마다 평균 손실과 평균 재구성 손실을 출력합니다.
자동 미분을 사용하여 그레이디언트 계산하기
아래 코드를 참고하세요.
사용자 정의 훈련 반복
드물게 fit() 메소드의 유연성이 원하는 만큼 충분하지 않을 수 있습니다.
예를 들어 두 개의 다른 옵티마이저를 사용해야 할 수도 있습니다.
그런데 fit() 메소드는 하나의 옵티마이저만 사용하므로 이를 위해선 훈련 반복을 직접 구현해야 합니다.
또는 의도한 대로 잘 동작하는지 확신을 갖기 위해 사용자 정의 훈련 반복을 쓸 수도 있습니다.
하지만 사용자 훈련 반복을 만들면 길고, 버그가 발생하기 쉽고, 유지 보수하기 어려운 코드가 만들어집니다.
이런 단점을 모두 감수하고도 사용자 정의 훈련 반복을 써야한다고 판단될 때만 사용하세요.
예시 코드를 보면서 살펴보겠습니다.
먼저 아래와 같이 간단한 모델이 있다고 하겠습니다.
l2_reg = keras.regularizers.l2(0.05)
model = keras.models.Sequential([
keras.layers.Dense(30, activation="elu", kernel_initializer="he_normal",
kernel_regularizer=l2_reg),
keras.layers.Dense(1, kernel_regularizer=l2_reg)
])그리고 샘플 배치를 추출하는 함수와 훈련 상태를 출력하는 함수를 만들어놓겠습니다.
# 훨씬 더 나은 데이터 API가 있지만 일단 여기선 만들어서 쓰겠습니다.
def random_batch(X, y, batch_size=32):
idx = np.random.randint(len(X), size=batch_size)
return X[idx], y[idx]
# 간편한 tqdm 라이브러리를 이용해 대체할 수 있습니다.
def print_status_bar(iteration, total, loss, metrics=None):
metrics = " - ".join(["{}: {:.4f}".format(m.name, m.result())
for m in [loss] + (metrics or [])])
end = "" if iteration < total else "\n"
print("\r{}/{} - ".format(iteration, total) + metrics,
end=end)이제 하이퍼파라미터를 설정하겠습니다.
n_epochs = 5
batch_size = 32
n_steps = len(X_train) // batch_size
optimizer = keras.optimizers.Nadam(learning_rate=0.01)
loss_fn = keras.losses.mean_squared_error
mean_loss = keras.metrics.Mean()
metrics = [keras.metrics.MeanAbsoluteError()]이렇게 하면 사용자 정의 훈련 반복을 만들 준비를 마쳤습니다.
아래와 같이 만들면 됩니다.
# 에포크를 위한 for문
for epoch in range(1, n_epochs + 1):
print("Epoch {}/{}".format(epoch, n_epochs))
# 에포크 안의 배치를 위한 for문
for step in range(1, n_steps + 1):
# 훈련 세트에서 배치를 랜덤하게 샘플링
X_batch, y_batch = random_batch(X_train_scaled, y_train)
# 배치 하나에 대한 예측을 만들고 손실을 계산
with tf.GradientTape() as tape:
y_pred = model(X_batch, training=True)
main_loss = tf.reduce_mean(loss_fn(y_batch, y_pred))
loss = tf.add_n([main_loss] + model.losses)
# 테이프를 사용해 훈련 가능한 각 변수에 대한 손실의 그레이디언트를 계산
gradients = tape.gradient(loss, model.trainable_variables)
# 이를 옵티마이저에 적용해 경사 하강법 수행
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
mean_loss(loss)
for metric in metrics:
metric(y_batch, y_pred)
print_status_bar(step * batch_size, len(y_train), mean_loss, metrics)
print_status_bar(len(y_train), len(y_train), mean_loss, metrics)
for metric in [mean_loss] + metrics:
metric.reset_states()만약 그레이디언트 클리핑을 하고 싶다면 clipnorm이나 clipvalue 하이퍼파라미터를 지정하세요.
만약 가중치에 다른 변환을 적용하려면 apply_gradients() 메소드를 호출하기 전 수행해야 합니다.
모델에 가중치 제한을 추가하면 apply_gradients() 다음에 이 제한을 적용하도록 코드를 수정해야 합니다.
for variable in model.variables:
if variable.constraint is not None:
variable.assign(variable.constraint(variable))텐서플로 함수와 그래프
텐서플로 1에서 그래프는 텐서플로 API의 핵심이라 피할 수가 없었습니다. 텐서플로 2에도 그래프가 있지만 이전만큼 핵심적이지 않고 사용하기 매우 쉽습니다.
텐서플로는 사용하지 않는 노드를 제거하고 표현을 단순화하는 등의 방식으로 계산 그래프를 최적화합니다.
따라서 일반적으로 텐서플로 함수는 원본 파이썬 함수보다 훨씬 빠르게 실행됩니다.
특히 복잡한 연산을 수행할 때 더 두드러집니다.
파이썬 함수를 빠르게 실행하려면 텐서플로 함수로 변환하세요.
또한 사용자 정의 손실, 지표, 층 또는 다른 어떤 사용자 함수를 작성하고
이를 케라스 모델에 사용할 때 케라스는 이 함수를 자동으로 텐서플로 함수로 변환합니다.
따라서, tf.function()을 사용할 필요가 없습니다.
Tip: 케라스가 파이썬 함수를 텐서플로 함수로 바꾸지 못하게 하려면 층이나 모델을 만들 때 dynamic=True로 지정합니다. 또는 모델의 compile() 메소드를 호출할 때 run_eagerly=True로 지정합니다.
텐서플로 함수 사용 방법
대부분의 경우 텐서플로 연산을 수행하는 파이썬 함수를 텐서플로 함수로 바꾸는 것은 간단합니다.
@tf.function 데코레이터를 쓰면 케라스가 알아서 나머지를 처리합니다.
하지만 몇 가지 지켜야 할 규칙이 있습니다.
- 넘파이나 표준 라이브러리를 포함해서 다른 라이브러리를 호출하면 트레이싱 과정에서 실행될 것입니다. 이 호출은 그래프에 포함되지 않습니다. 실제 텐서플로 그래프는 텐서플로 구성 요소만 포함할 수 있습니다. 따라서 트레이싱 과정에서 코드가 실행되는 것을 원하지 않는다면 np.sum() 대신에 tf.reduce_sum()을, sorted() 대신에 tf.sort()와 같이 사용해야 합니다.
- 다른 파이썬 함수나 텐서플로 함수를 호출할 수 있습니다. 하지만 텐서플로가 계산 그래프에 있는 이 함수들의 연산을 감지하므로 동일한 규칙을 따릅니다. 이런 함수들은 @tf.function을 적용할 필요가 없습니다.
- 함수에서 텐서플로 변수를 만든다면 처음 호출될 때에만 수행되어야 합니다. 아니면 예외가 발생합니다. 일반적으로 텐서플로 함수 밖에서 변수를 생성하는 게 좋습니다. 변수에 새로운 값을 할당하려면 = 연산자 대신 assign() 메소드를 사용하세요.
- 파이썬 함수의 소스 코드는 텐서플로에서 사용 가능해야 합니다. 만약 소스 코드를 사용할 수 없다면 그래프 생성 과정이 실패하거나 일부 기능을 사용할 수 없게 됩니다.
- 텐서플로는 텐서나 데이터셋을 순회하는 for문만 감지합니다. 따라서 for i in range(x)와 같은 방식의 for문 대신 for i in tf.range(x)를 사용해야 합니다. 그렇지 않으면 이 for문이 그래프에 표현되지 못하고 트레이싱 단계에서 실행됩니다.
- 성능면에서는 반복문을 쓰기보다는 가능하다면 벡터화된 구현을 쓰는 게 좋습니다.
'DATA > 머신 러닝' 카테고리의 다른 글
| [머신 러닝] RNN과 CNN을 사용해 시퀀스 처리하기 (0) | 2022.02.15 |
|---|---|
| [머신 러닝] 합성곱 신경망을 사용한 컴퓨터 비전 (0) | 2022.02.13 |
| [머신 러닝] 머신러닝을 위한 텐서플로 (0) | 2022.02.02 |
| [머신 러닝] 심층 신경망 훈련하기 (0) | 2022.02.01 |
| [머신 러닝] 신경망 하이퍼파라미터 튜닝하기 (0) | 2022.01.23 |