다층 퍼셉트론과 역전파
다층 퍼셉트론은 입력층 하나와 은닉층이라 불리는 하나 이상의 TLU 층과 출력층으로 구성됩니다.
입력층과 가까운 층을 하위 층, 출력층에 가까운 층을 상위 층이라 부릅니다.
출력층을 제외하고 모든 층은 편향 뉴런을 포함하며 다음 층과 완전히 연결돼 있습니다.
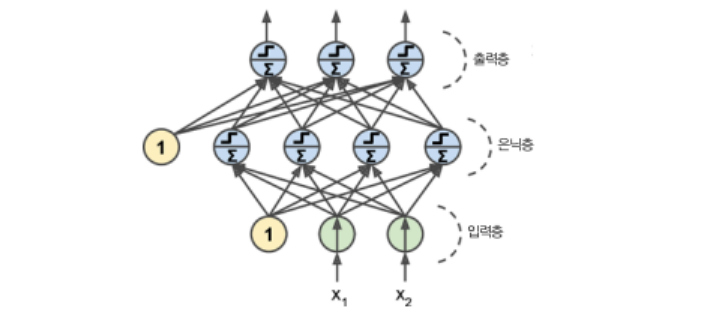
은닉층을 여러 개 쌓아 올린 인공 신경망을 심층 신경망(deep neural network, DNN)이라고 합니다.
딥러닝은 심층 신경망을 연구하는 분야이며 조금 더 일반적으로는 연산이 연속하여 길게 연결된 모델을 연구합니다.
다층 퍼셉트론을 훈련할 방법을 찾는 연구가 긴 시간 지속되다가
데이비드 루멜하트, 제프리 힌턴, 로날드 윌리엄스가 역전파 훈련 알고리즘을 소개했습니다.
이 알고리즘은 효율적 기법으로 그레이디언트를 자동으로 계산하는 경사 하강법입니다.
네트워크를 정방향으로 한 번, 역방향으로 한 번 통과하는 것만으로 모든 모델 파라미터에 대한
네트워크 오차의 그레이디언트를 계산할 수 있습니다.
이 알고리즘을 조금 더 자세히 살펴보겠습니다.
한 번에 하나의 미니배치씩 진행해 전체 훈련 세트를 처리합니다.
이 과정을 여러 번 반복하는 데 각 반복을 에포크라고 합니다.
각 미니배치를 이용해 정방향 계산을 합니다.
이 과정은 역방향 계산을 위해 중간 계산값을 모두 저장하는 것 외에는 예측을 만드는 것과 정확히 같습니다.
그 다음 알고리즘이 손실 함수를 이용해 출력 오차를 측정합니다.
이제 각 출력 연결이 이 오차에 기여하는 정도를 계산합니다.
이 알고리즘은 또 다시 이전 층의 연결 가중치가 이 오차의 기여 정도에 얼마나 기여했는지 측정합니다.
마지막으로 알고리즘은 경사 하강법을 수행해
방금 계산한 오차 그레이디언트를 사용해 네트워크에 있는 모든 연결 가중치를 수정합니다.
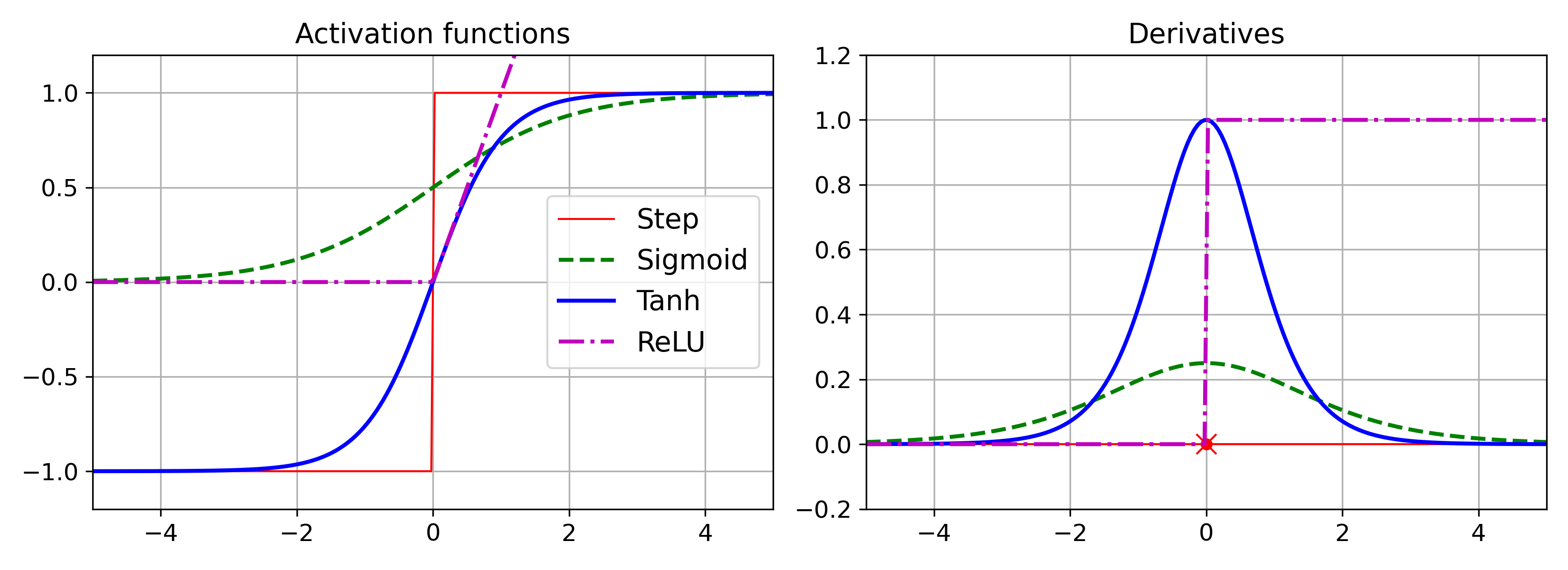
이 알고리즘을 잘 작동시키기 위해 논문 저자들은 다층 퍼셉트론 구조의 계단 함수를 시그모이드로 바꿨습니다.
계단 함수에는 수평선밖에 없어서 계산할 그레이디언트가 없기 때문입니다.
역전파 알고리즘은 시그모이드 외에도 다른 활성화 함수와도 사용될 수 있습니다.
널리 쓰이는 두 개의 활성화 함수는 다음과 같습니다.
- 하이퍼볼릭 탄젠트 함수 (쌍곡 탄젠트 함수): \(tanh(z) = 2\sigma(2z) - 1\), 시그모이드 함수처럼 이 활성화 함수도 S자 모양이고 연속적이며 미분 가능합니다. 출력 범위가 -1에서 1 사이이고, 이 범위는 훈련 초기에 각 층의 출력을 원점 근처로 모으는 경향이 있습니다. 이는 종종 빠른 수렴을 도와줍니다.
- ReLU 함수: \(ReLU(z) = max(0, z)\), ReLU 함수는 연속적이지만 \(z = 0\)에서 미분가능하지 않습니다. 그러나 실제로는 잘 작동하고 계산 속도가 빠르다는 장점이 있어 기본 활성화 함수가 되었습니다.
이런 활성화 함수들이 왜 필요할까요?
선형 변환을 여러 개 연결해도 얻을 수 있는 것은 선형 변환뿐이기 때문입니다.
따라서 층 사이에 비선형층을 추가하지 않으면 아무리 층을 많이 쌓아도 하나의 층과 동일해집니다.
이런 층으로는 복잡한 문제를 풀 수 없으므로 활성화 함수가 필요한 것입니다.
여태 봤던 활성화 함수들을 아래 그림에 나타냈습니다.
회귀를 위한 다층 퍼셉트론
다층 퍼셉트론은 회귀에 사용할 수 있습니다.
값 하나를 예측하는 데 출력 뉴런이 하나만 필요합니다.
이 뉴런의 출력이 예측한 값입니다.
다변량 회귀(동시에 여러 값을 예측하는 경우)에서는 출력 차원마다 출력 뉴런이 하나씩 필요합니다.
일반적으로 회귀용 다층 퍼셉트론을 만들 때 출력 뉴런에 활성화 함수를 사용하지 않고 범위 제한이 되지 않게 합니다.
하지만 출력이 항샹 양수여야한다면 ReLU나 softplus 활성화 함수를 사용할 수 있습니다.
softplus 함수는 ReLU의 변종으로 다음과 같습니다.
\[ softplus(z) = log(1 + exp(z)) \]
이 함수는 z가 작을수록 0에 가까워지고 z가 클수록 z에 가까워집니다.
마지막으로 어떤 범위 안의 값을 예측하고 싶다면
시그모이드 함수나 하이퍼볼릭 탄젠트 함수를 사용하고 레이블의 스케일을 적절한 범위로 조정할 수 있습니다.
훈련에 사용하는 손실 함수는 전형적으로 평균 제곱 오차입니다.
하지만 훈련 세트에 이상치가 많다면 대신 평균 절댓값 오차를 사용할 수 있습니다.
또는 이 둘을 조합한 후버 손실을 사용할 수 있습니다.
아래는 회귀 다층 퍼셉트론의 전형적인 구조입니다.
| 하이퍼파라미터 | 일반적인 값 |
| 입력 뉴런 수 | 특성마다 하나 |
| 은닉층 수 | 문제에 따라 다름, 일반적으로 1에서 5 사이 |
| 은닉층의 뉴런 수 | 문제에 따라 다름, 일반적으로 10에서 100 사이 |
| 출력 뉴런 수 | 예측 차원마다 하나 |
| 은닉층의 활성화 함수 | ReLU(또는 SELU) |
| 출력층의 활성화 함수 | 없음, 또는 ReLU/softplus나 logistic(sigmoid)/tanh 사용 |
| 손실 함수 | MSE나 이상치가 있다면 MAE/Huber |
분류를 위한 다층 퍼셉트론
다층 퍼셉트론은 분류 작업에도 사용 가능합니다.
이진 분류 문제에서는 로지스틱 활성화 함수를 가진 하나의 출력 뉴런만 필요합니다.
출력은 0과 1 사이의 실수입니다. 이를 양성 클래스에 대한 확률로 해석할 수도 있습니다.
다층 퍼셉트론은 다중 레이블 이진 분류 문제를 쉽게 해결할 수 있습니다.
이 때에는 로지스틱 활성화 함수를 가진 레이블 개수 만큼의 출력 뉴런이 필요합니다.
각 샘플이 여러 클래스 중 한 클래스에만 속할 수 있다면 클래스마다 하나의 출력 뉴런이 필요합니다.
출력층에는 소프트맥스 활성화 함수를 사용해야 합니다.
소프트맥스 함수는 예측 확률을 0과 1 사이로 만들고 더했을 때 1이 되도록 만듭니다.
이를 다중 분류라고 부릅니다.

확률 분포를 예측해야 하므로 손실 함수에는 일반적으로 크로스 엔트로피 손실을 선택하는 것이 좋습니다.
| 하이퍼 파라미터 | 이진 분류 | 다중 레이블 분류 | 다중 분류 |
| 입력층과 은닉층 | 회귀와 동일 | 회귀와 동일 | 회귀와 동일 |
| 출력 뉴런 수 | 1개 | 레이블마다 1개 | 클래스마다 1개 |
| 출력층의 활성화 함수 | 로지스틱 함수 | 로지스틱 함수 | 소프트맥스 함수 |
| 손실 함수 | 크로스 엔트로피 | 크로스 엔트로피 | 크로스 엔트로피 |
케라스로 다층 퍼셉트론 구현하기
tensorflow 2, tf.keras를 이용하겠습니다.
시퀀셜 API를 사용하여 이미지 분류기 만들기
아래 코드를 참고하세요.
시퀀셜 API를 사용하여 회귀용 다층 퍼셉트론 만들기
아래 코드를 참고하세요.
함수형 API를 사용해 복잡한 모델 만들기
순차적이지 않은 신경망의 한 예는 와이드 & 딥 신경망입니다.
이 신경망은 아래 그림과 같이 입력의 일부 또는 전체가 출력층에 바로 연결됩니다.
이 구조를 사용하면 신경망이 (쌓은 층을 사용한)복잡한 패턴과
(짧은 경로를 사용한)간단한 규칙을 모두 학습할 수 있습니다.
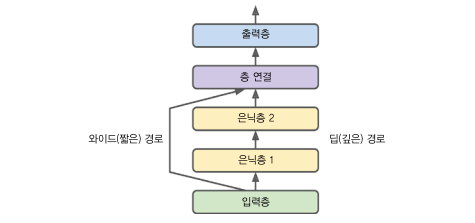
이런 신경망을 만들어보겠습니다.
아래 그림과 같이 일부 특성은 짧은 경로로 전달하고
다른 특성들은 (중복될 수 있습니다.) 깊은 경로로 전달하고 싶을 수도 있습니다.
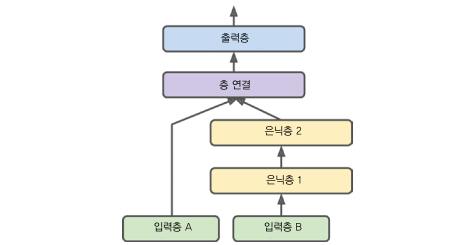
위와 같은 모델을 만들어보겠습니다.
여러 개의 출력이 필요한 경우도 많습니다.
- 말 그대로 여러 출력이 필요한 작업인 경우
- 동일한 데이터에서 독립적인 여러 작업을 수행할 경우, 물론 작업마다 새로운 신경망을 훈련할 수 있지만 신경망이 여러 작업에 걸쳐 유용한 특성을 학습할 수 있기 때문에 작업마다 하나의 출력을 가진 단일 신경망을 훈련하는 것이 좀 더 나은 결과를 냅니다.
- 규제 기법으로 사용하는 경우, 예를 들어 신경망 구조 안에 보조 출력을 추가할 수 있습니다. 보조 출력을 사용해 하위 네트워크가 나머지 네트워크에 의존하지 않고 그 자체로 유용한 것을 학습하는지 확인 가능합니다.
위와 같은 경우들 중 보조 출력을 사용하는 경우를 다뤄보겠습니다.
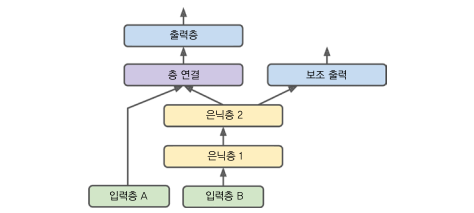
위 그림과 같은 모델을 만들어보겠습니다.
서브클래싱 API로 동적 모델 만들기
앞서 다른 시퀀셜 API와 함수형 API는 모두 선언적입니다.
사용할 층과 연결 방식을 먼저 정의하고, 그 다음 모델에 데이터를 주입하여 훈련이나 추론을 할 수 있습니다.
이 방식에는 다음과 같은 장점이 있습니다.
- 모델을 저장하거나 복사, 공유하기 쉽습니다.
- 모델의 구조를 출력하거나 분석하기 좋습니다.
- 프레임워크가 크기를 짐작하고 타입을 확인하여 에러를 일찍 발견할 수 있습니다. (즉, 모델에 데이터가 주입되기 전에)
- 전체 모델이 층으로 구성된 정적 그래프이므로 디버깅하기도 쉽습니다.
이런 장점들을 많이 갖지만 정적이라는 것은 단점이 되기도 합니다.
어떤 모델은 반복문을 포함하고 다양한 크기를 다뤄야 하며 조건문을 가지는 등
여러 가지 동적인 구조를 필요로 합니다.
이런 경우 좀 더 명령형 프로그래밍 스타일이 필요하다면 서브클래싱 API가 정답입니다.
이를 이용한 모델을 만들어보겠습니다.
함수형 API를 만드는 것과 비슷하지만
Input 클래스의 객체를 만들 필요가 없습니다.
대신 call() 메소드의 inputs 매개변수를 사용합니다.
생성자에 있는 층 구성과 call() 메소드에 있는 정방향 계산을 분리했습니다.
주된 차이점은 call() 메소드 안에서 어떤 계산이든 할 수 있다는 것입니다.
for, if, 텐서플로 저수준 연산 등을 사용할 수 있습니다.
유연성이 높아지는 대신 그에 따른 비용이 발생합니다.
모델 구조각 call() 메소드 안에 숨겨져 있기 때문에
케라스가 이를 쉽게 분석할 수 없습니다.
즉 모델을 저장하거나 복사할 수 없습니다.
summary() 메소드를 호출하면 층의 목록만 나열되고 층 간의 연결 정보를 얻을 수 없습니다.
또한 케라스가 타입과 크기를 미리 확인할 수 없어 실수가 발생하기 쉽습니다.
이런 단점들 때문에 높은 유연성이 필요한 게 아니라면
시퀀셜 API와 함수형 API를 사용하는 게 좋습니다.
'DATA > 머신 러닝' 카테고리의 다른 글
| [머신 러닝] 콜백 사용하기 (0) | 2022.01.22 |
|---|---|
| [머신 러닝] 모델 저장과 복원 (0) | 2022.01.22 |
| [머신 러닝] 퍼셉트론 (0) | 2022.01.21 |
| [머신 러닝] 비지도 학습 (0) | 2022.01.19 |
| [머신 러닝] 차원 축소 (0) | 2022.01.18 |